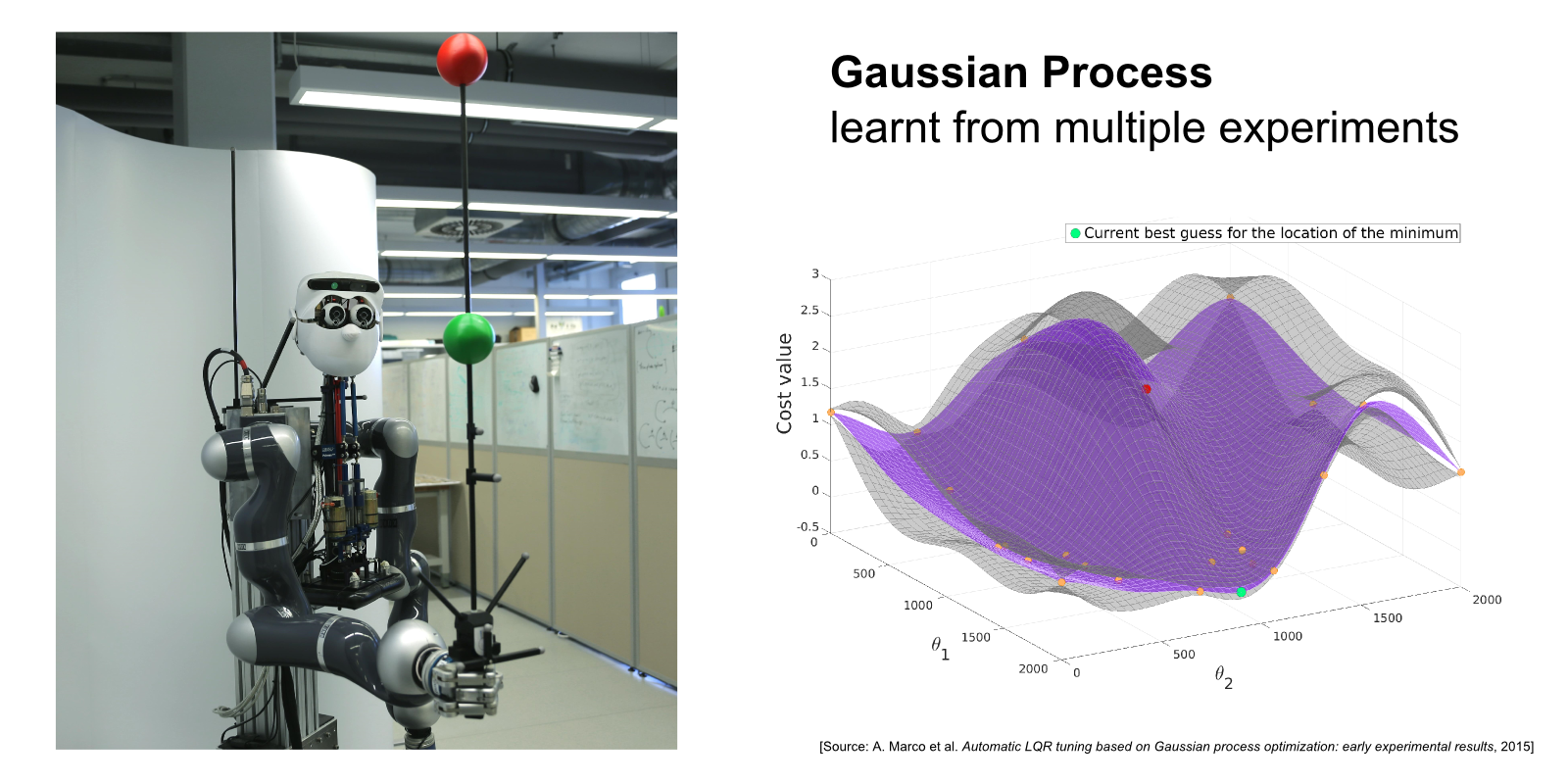
The robot Apollo (on the LEFT) learns to balance a pole as steady as possible using automatic LQR tuning. On the RIGHT, the Gaussian Process underlying the auto-tuning method is shown, which represents the belief about the cost function after several experimental runs. The pole balancing problem on Apollo serves as a demonstrator for our research on automatic controller tuning and design.
Autonomous systems such as humanoid robots are characterized by a multitude of feedback control loops operating at different hierarchical levels and time-scales. Designing and tuning these controllers typically requires significant manual modeling and design effort and exhaustive experimental testing. For managing the ever greater complexity and striving for greater autonomy of future systems, it is desirable to transfer some of the control design efforts to automatic or semi-automatic routines. In our research, we leverage automatic control theory, machine learning, and optimization to develop automatic design and tuning approaches.
In [ ], we propose a framework where an initial controller is automatically improved based on observed performance from a limited number of experiments. This scenario is relevant, for example, in many industrial settings, where an initial tuning shall be improved without much user intervention and with limited resources (e.g. experimental time on the plant). Entropy Search [ ] serves as the underlying optimizer for the auto-tuning method. It represents the latent control objective as a Gaussian process (see above figure) and suggests new controllers so as to maximize the information gain from each experiment. We validate the developed approaches on the experimental platforms at our department (see figure).
Aspects to be taken into account when developing automatic methods concern, for example, the available prior information (e.g. is a model or initial controller available?), operational constraints (can tuning be done off-line or during operation?), available resources (how many experiments can be done?), and safety requirements (is the controller allowed to “fail” during training?). We are interested in developing specific methods for some of these scenarios, as well as understanding in general, how far we can push “black-box” control design methods.