2023
Berenz, V., Widmaier, F., Guist, S., Schölkopf, B., Büchler, D.
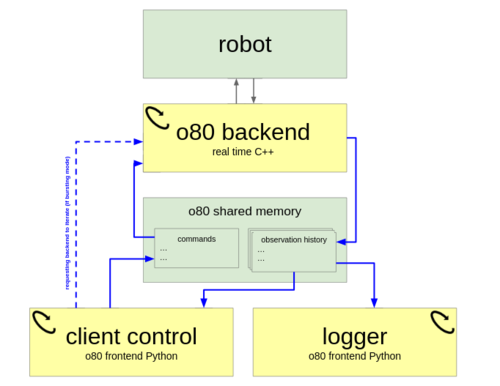
Synchronizing Machine Learning Algorithms, Realtime Robotic Control and Simulated Environment with o80
Robot Software Architectures Workshop (RSA) 2023, ICRA, 2023 (techreport)

2015
Abbott, T., Abdalla, F. B., Allam, S., Amara, A., Annis, J., Armstrong, R., Bacon, D., Banerji, M., Bauer, A. H., Baxter, E., others,
Cosmology from Cosmic Shear with DES Science Verification Data
arXiv preprint arXiv:1507.05552, 2015 (techreport)
Jarvis, M., Sheldon, E., Zuntz, J., Kacprzak, T., Bridle, S. L., Amara, A., Armstrong, R., Becker, M. R., Bernstein, G. M., Bonnett, C., others,
The DES Science Verification Weak Lensing Shear Catalogs
arXiv preprint arXiv:1507.05603, 2015 (techreport)
2013
Hennig, P.
Animating Samples from Gaussian Distributions
(8), Max Planck Institute for Intelligent Systems, Tübingen, Germany, 2013 (techreport)
Hogg, D. W., Angus, R., Barclay, T., Dawson, R., Fergus, R., Foreman-Mackey, D., Harmeling, S., Hirsch, M., Lang, D., Montet, B. T., Schiminovich, D., Schölkopf, B.
Maximizing Kepler science return per telemetered pixel: Detailed models of the focal plane in the two-wheel era
arXiv:1309.0653, 2013 (techreport)
Montet, B. T., Angus, R., Barclay, T., Dawson, R., Fergus, R., Foreman-Mackey, D., Harmeling, S., Hirsch, M., Hogg, D. W., Lang, D., Schiminovich, D., Schölkopf, B.
Maximizing Kepler science return per telemetered pixel: Searching the habitable zones of the brightest stars
arXiv:1309.0654, 2013 (techreport)
2012
Grosse-Wentrup, M., Schölkopf, B.
High Gamma-Power Predicts Performance in Brain-Computer Interfacing
(3), Max-Planck-Institut für Intelligente Systeme, Tübingen, February 2012 (techreport)
2011
Seldin, Y., Laviolette, F., Shawe-Taylor, J., Peters, J., Auer, P.
PAC-Bayesian Analysis of Martingales and Multiarmed Bandits
Max Planck Institute for Biological Cybernetics, Tübingen, Germany, May 2011 (techreport)
Schuler, C., Hirsch, M., Harmeling, S., Schölkopf, B.
Non-stationary Correction of Optical Aberrations
(1), Max Planck Institute for Intelligent Systems, Tübingen, Germany, May 2011 (techreport)
Nickisch, H., Seeger, M.
Multiple Kernel Learning: A Unifying Probabilistic Viewpoint
Max Planck Institute for Biological Cybernetics, March 2011 (techreport)
Langovoy, M., Wittich, O.
Multiple testing, uncertainty and realistic pictures
(2011-004), EURANDOM, Technische Universiteit Eindhoven, January 2011 (techreport)
Sra, S.
Nonconvex proximal splitting: batch and incremental algorithms
(2), Max Planck Institute for Intelligent Systems, Tübingen, Germany, 2011 (techreport)
2010
Langovoy, M., Wittich, O.
Computationally efficient algorithms for statistical image processing: Implementation in R
(2010-053), EURANDOM, Technische Universiteit Eindhoven, December 2010 (techreport)
Seeger, M., Nickisch, H.
Fast Convergent Algorithms for Expectation Propagation Approximate Bayesian Inference
Max Planck Institute for Biological Cybernetics, December 2010 (techreport)
Seldin, Y.
A PAC-Bayesian Analysis of Graph Clustering and Pairwise Clustering
Max Planck Institute for Biological Cybernetics, Tübingen, Germany, September 2010 (techreport)
Tandon, R., Sra, S.
Sparse nonnegative matrix approximation: new formulations and algorithms
(193), Max Planck Institute for Biological Cybernetics, Tübingen, Germany, September 2010 (techreport)
Langovoy, M., Wittich, O.
Robust nonparametric detection of objects in noisy images
(2010-049), EURANDOM, Technische Universiteit Eindhoven, September 2010 (techreport)
Seeger, M., Nickisch, H.
Large Scale Variational Inference and Experimental Design for Sparse Generalized Linear Models
Max Planck Institute for Biological Cybernetics, August 2010 (techreport)
Jegelka, S., Bilmes, J.
Cooperative Cuts for Image Segmentation
(UWEETR-1020-0003), University of Washington, Washington DC, USA, August 2010 (techreport)
Barbero, A., Sra, S.
Fast algorithms for total-variationbased optimization
(194), Max Planck Institute for Biological Cybernetics, Tübingen, Germany, August 2010 (techreport)
Nickisch, H., Rasmussen, C.
Gaussian Mixture Modeling with Gaussian Process Latent Variable Models
Max Planck Institute for Biological Cybernetics, June 2010 (techreport)
Sra, S.
Generalized Proximity and Projection with Norms and Mixed-norms
(192), Max Planck Institute for Biological Cybernetics, Tübingen, Germany, May 2010 (techreport)
Jegelka, S., Bilmes, J.
Cooperative Cuts: Graph Cuts with Submodular Edge Weights
(189), Max Planck Institute for Biological Cybernetics, Tuebingen, Germany, March 2010 (techreport)
Steudel, B., Ay, N.
Information-theoretic inference of common ancestors
Computing Research Repository (CoRR), abs/1010.5720, pages: 18, 2010 (techreport)
2009
Nickisch, H., Kohli, P., Rother, C.
Learning an Interactive Segmentation System
Max Planck Institute for Biological Cybernetics, December 2009 (techreport)
Langovoy, M., Wittich, O.
Detection of objects in noisy images and site percolation on square lattices
(2009-035), EURANDOM, Technische Universiteit Eindhoven, November 2009 (techreport)
Harmeling, S., Sra, S., Hirsch, M., Schölkopf, B.
An Incremental GEM Framework for Multiframe Blind Deconvolution, Super-Resolution, and Saturation Correction
(187), Max Planck Institute for Biological Cybernetics, Tübingen, Germany, November 2009 (techreport)
Hirsch, M., Sra, S., Schölkopf, B., Harmeling, S.
Efficient Filter Flow for Space-Variant Multiframe Blind Deconvolution
(188), Max Planck Institute for Biological Cybernetics, Tübingen, Germany, November 2009 (techreport)
Langovoy, M.
Algebraic polynomials and moments of stochastic integrals
(2009-031), EURANDOM, Technische Universiteit Eindhoven, October 2009 (techreport)
Hennig, P.
Expectation Propagation on the Maximum of Correlated Normal Variables
Cavendish Laboratory: University of Cambridge, July 2009 (techreport)
Gretton, A., Györfi, L.
Consistent Nonparametric Tests of Independence
(172), Max Planck Institute for Biological Cybernetics, Tübingen, Germany, July 2009 (techreport)
Shelton, J., Blaschko, M., Bartels, A.
Semi-supervised subspace analysis of human functional magnetic resonance imaging data
(185), Max Planck Institute for Biological Cybernetics, Tübingen, Germany, May 2009 (techreport)
Langovoy, M.
Model selection, large deviations and consistency of data-driven tests
(2009-007), EURANDOM, Technische Universiteit Eindhoven, March 2009 (techreport)
2008
Nowozin, S., Tsuda, K.
Frequent Subgraph Retrieval in Geometric Graph Databases
(180), Max-Planck Institute for Biological Cybernetics, Tübingen, Germany, November 2008 (techreport)
Giesen, J., Maier, M., Schölkopf, B.
Simultaneous Implicit Surface
Reconstruction and Meshing
(179), Max-Planck Institute for Biological Cybernetics, Tübingen, Germany, November 2008 (techreport)
Blaschko, M., Gretton, A.
Taxonomy Inference Using Kernel Dependence
Measures
(181), Max-Planck Institute for Biological Cybernetics, Tübingen, Germany, November 2008 (techreport)
Gehler, P., Nowozin, S.
Infinite Kernel Learning
(178), Max-Planck Institute for Biological Cybernetics, Tübingen, Germany, October 2008 (techreport)
Seeger, M., Nickisch, H.
Large Scale Variational Inference and Experimental Design for Sparse Generalized Linear Models
(175), Max-Planck Institute for Biological Cybernetics, Tübingen, Germany, September 2008 (techreport)
Sra, S.
Block-Iterative Algorithms for
Non-Negative Matrix Approximation
(176), Max-Planck Institute for Biological Cybernetics, Tübingen, Germany, September 2008 (techreport)
Sra, S., Jegelka, S., Banerjee, A.
Approximation Algorithms for Bregman
Clustering Co-clustering and Tensor Clustering
(177), Max-Planck Institute for Biological Cybernetics, Tübingen, Germany, September 2008 (techreport)
Dhillon, P., Nowozin, S., Lampert, C.
Combining Appearance and Motion for Human
Action Classification in Videos
(174), Max-Planck-Institute for Biological Cybernetics, Tübingen, Germany, August 2008 (techreport)
Kim, K., Kwon, Y.
Example-based Learning for Single-image
Super-resolution and JPEG Artifact Removal
(173), Max-Planck-Institute for Biological Cybernetics, Tübingen, Germany, August 2008 (techreport)
Chiappa, S.
Unsupervised Bayesian Time-series Segmentation based on Linear Gaussian State-space Models
(171), Max-Planck-Institute for Biological Cybernetics, Tübingen, Germany, June 2008 (techreport)
Kim, D., Sra, S., Dhillon, I.
A New Non-monotonic Gradient Projection Method for the Non-negative Least Squares Problem
(TR-08-28), University of Texas, Austin, TX, USA, June 2008 (techreport)
Sra, S., Kim, D., Schölkopf, B.
Non-monotonic Poisson Likelihood Maximization
(170), Max-Planck Institute for Biological Cybernetics, Tübingen, Germany, June 2008 (techreport)
Gretton, A., Borgwardt, K., Rasch, M., Schölkopf, B., Smola, A.
A Kernel Method for the Two-sample Problem
(157), Max-Planck-Institute for Biological Cybernetics Tübingen, April 2008 (techreport)
Hein, M., Steinke, F., Schölkopf, B.
Energy Functionals for
Manifold-valued Mappings and
Their Properties
(167), Max Planck Institute for Biological Cybernetics, Tübingen, January 2008 (techreport)
2007
Harmeling, S., Toussaint, M.
Bayesian Estimators for Robins-Ritovs Problem
(EDI-INF-RR-1189), School of Informatics, University of Edinburgh, October 2007 (techreport)
Walder, C., Chapelle, O.
Learning with Transformation Invariant Kernels
(165), Max Planck Institute for Biological Cybernetics, Tübingen, Germany, September 2007 (techreport)
Kulis, B., Sra, S., Jegelka, S.
Scalable Semidefinite Programming using Convex Perturbations
(TR-07-47), University of Texas, Austin, TX, USA, September 2007 (techreport)